[번역] Unicode 이모티콘에 얽힌 이것저것 (이모티콘 표준과 프로그래밍 핸들링)
본 포스팅은 Unicode 絵文字にまつわるあれこれ (絵文字の標準とプログラム上でのハンドリング) 을 번역한 글입니다.
제 일본어 실력으로 인하여 오역이나 오타가 발생할 수 있습니다.
안녕하세요. 주식회사 mixi 에서 가족 앨범 mitene 라는 앱 개발을 하는 @_sobataro 입니다. 이 글에서는 Emoji 표준과 처리에 대한 정리입니다.
또한, 이 글은 mixi Group Advent Calendar 2016 18일째 글입니다. 어제는 @radioboo 님의 IGListKit에서 Feed UI를 리팩토링 입니다. 내일은 @yusuke_tashiro 씨 담당입니다.
Part I.
- Unicode 이모티콘 표준에 대해
- 심심한 사람을 위해서. 안 읽어도 된다.
Part II.
- 실제로 프로그램으로 이모티콘을 처리에 문제가 되는 부분에 대해서
- Unicode 이모티콘 문자 수 (Grapheme Cluster 개수)를 엄격하게 제대로 계산하려면 최신 Unicode (현시점에서는 Unicode 9.0) 이후에 대응한 Parser가 필요
- ActiveSupport 5.0 이나 Swift 3.1 에서는 Unicode 8.0까지만 대응하고 있다
- Ruby 2.4.0 이후는 Unicode 9.0를 대응하고 있다
- 대충 구현해도 되면 그럭저럭 쉽게 할 수 있다
- 환경에 따라서 unicode 이모티콘 스타일 (텍스트 스타일 or 이모티콘 스타일)이 바뀐다
- 검증용 페이지 가 있음으로 사용해주세요
- 각 환경에서 이모티콘 스타일을 통일하고 싶다 / 이모티콘 파일을 앱이나 서비스에 포함해 제공하고 싶다 / 서버 사이드에서 이모티콘을 이용하고 싶다
- Twitter 의 twemoji 이나 google 의 noto-emoji 를 사용하는 게 좋다
Part I. Unicode 이모티콘 표준 (심심한 사람용)
먼저 Unicode 이모티콘 표준에 대한 자료를 정리합니다.
주의 : 이 파트는 내용이 장황하므로 심심한 사람용입니다.
- Unicode® Emoji
- Unicode Emoji 표준과 관련 자료 페이지 모음
- UTR #51: Unicode Emoji (Version 4.0, 현재 최신버전), Proposed Update UTR #51: Unicode Emoji (Version 5.0, 최신 초안)
- Unicode emoji 의 상호운용성을 높이기 위한 디자인 가이드라인. 그리고 이 문서는 unicode emoji 목록 및 이후에 이야기하는 emoji Presentation Style, skin tone modifier에 대한 목록도 포함한다
- Unicode emoji version 4.0 와 5.0 (초안 버전)에서 주로 이모티콘 Parse에 관한 내용이 크게 다르기 때문에 이 차이에 대해서도 나중에 다룬다.
- (참고) 앞으로의 이모티콘 구현 지침, UTR #51“Unicode Emoji”란 무엇인가: 이모티콘의 역사와 미래를 근거로 UTR#51을 이야기한 글. 앞으로 프로그램에서 unicode 이모티콘을 처리하려고 생각하고 있다면 필독!
- USA #29: Unicode Text Segmentation (Version 9.0.0, 현재 최신 버전), Proposed Update USA #29: Unicode Text Segmentation (Version 10.0.0, 최신 초안)
- Unicode는 “문자” 또는 “단어”의 구분을 어떻게 결정하는가를 정의한 문서.
- Unicode Version 9.0.0와 10.0.0 (초안)에서 주로 이모티콘에 관한 내용이 변경되었다.
이후에서는 주로 UTR #51 Version 5.0 (초안)에 대해 소개합니다.
Unicode Emoji 목록
Unicode emoji 데이터베이스는 emoji-data 에 포함되어 있습니다. 이 가운데에는 unicode emoji version 4.0과 5.0 중에서도 1126문자를 ‘이모티콘’이라고 정의하고 있습니다.
또한 Full Emoji Data, v4.0 및 http://unicode.org/emoji/charts-beta/full-emoji-list.html 에도 unicode emoji 목록이 있습니다. 이곳은 이모티콘 1문자 단위에 대하여 그 문자의 설명과 unicode emoji에 수록된 시기, 다양한 환경에서 어떻게 표시되는지에 대한 사항을 확인할 수 있습니다.
문자 표시 (Presentation): 텍스트 스타일과 이모티콘 스타일
일부 unicode emoji는 텍스트 스타일과 이모티콘 스타일, 두 가지 스타일 (presentation style)을 갖습니다. 이 구별은 2012-01-31에 발표된 Unicode 6.1 에서 도입된 것입니다.
UTR #51에 따르면 하나의 이모티콘이 텍스트 스타일과 이모티콘 스타일 중 어느 쪽을 표시할지는 다음의 요소에 의해 결정됩니다.
각 문자가 가지는 Emoji_Presentation property
emoji-data 는 각 unicode 문자에 Emoji_Presentation 속성을 Yes (이모티콘 스타일) 또는は No (텍스트 스타일)에 규정되어 있습니다.
| Emoji_Presentation | 기본 스타일 | 예시 |
|---|---|---|
No |
텍스트 | U+0023 1 U+00A9 ©️ U+2702 ✂️ |
Yes |
이모티콘 | U+2705 ✅ U+1F440 👀 |
그러나 이것은 기본값이며, 아래의 요인에 따라 스타일을 덮어쓸 수 있습니다.
문자 뒤에 붙이는 variation selector
Unicode에는 변이 글자를 처리하는 variation selector라는 구조가 있고, 이것을 이모티콘 스타일 지정에 사용합니다.
이모티콘 뒤에 U+FE0E VARIATION SELECTOR-15 (TPVS) 또는 U+FE0F VARIATION SELECTOR-16 (EPVS) 를 붙여 스타일을 지정합니다.
테스트 환경 (OS X El Capitan + Chrome 54)에서는 Qiita에서 variation selector를 붙여도 스타일을 변경할 수 없기 때문에 별도 Gist으로 준비했습니다.
- sobataro/emoji_list.txt (기본 이모티콘, TPVS 포함 이모티콘, EPVS 포함 이모티콘 목록)
- sobataro/emoji_list.rb (↑를 생성한 스크립트)
환경에 따라 다르지만 (자세한 내용은 아래 참조), 예를 들어 TextEdit.app은 다음과 같이 표시됩니다.
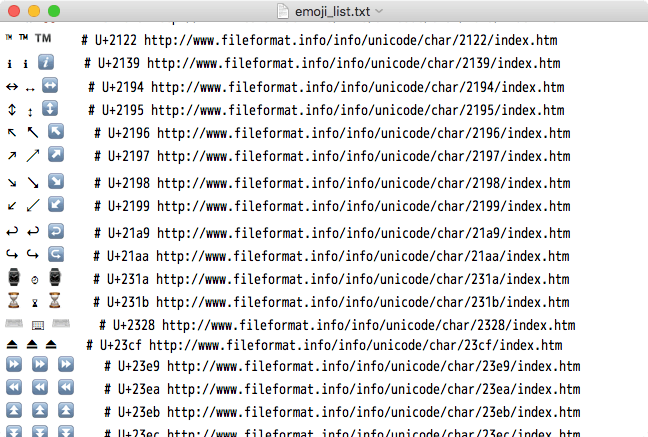
위 예에 따르면, 예를 들어 다음과 같은 느낌입니다.
| 문자 | Emoji_ Presentation | VS 미포함 | TPVS 포함 | EPVS 포함 |
|---|---|---|---|---|
U+2122 TRADE MARK SIGN ™ |
No |
text | text | emoji |
U+231B HOURGLASS ⌛ |
Yes |
emoji | text | emoji |
U+23EB BLACK UP-POINTING DOUBLE TRIANGLE ⏫ |
Yes |
emoji | emoji (※) | emoji |
(※ 해당하는 Glyph가 OS X가 가진 폰트 파일에 존재하지 않기 때문에 이모티콘 스타일로 대체하여 표시되고 있습니다.)
기타
Emoji Locale Extension 및 Emoji Script 를 사용하는 방법도 있지만, 여기에서는 생략합니다.
또한 환경에 따라 위의 Emoji_Presentation property를 무시하는 것도 UTR #51에서 허용하고 있습니다. 다음 표에서는 가장 오른쪽의 “with neither” 열처럼, 환경 (“word processing” 혹은 “texting, chats”)에 의해 variation selector가 없을 때의 기본 스타일이 변경되게 되어있습니다.
 (표: UTR #51 인용)
(표: UTR #51 인용)
Emoji Sequence
Unicode emoji에는 단일 코드 포인트로 구성된 singleton과 복수 코드 포인트로 구성된 emoji sequence 가 있습니다. 특히 emoji sequence는 다음과 같이 emoji core sequence와 emoji zwj sequence로 구분되며, 게다가 전자는 3개의 종류가 있습니다.
emoji
├ singleton (단일 코드 포인트로 구성된 이모티콘)
└ emoji sequence (복수 코드 포인트로 구성된 이모티콘)
├ emoji core sequence (일반 이모티콘)
│ ├ emoji combining sequence (결합 문자)
│ ├ emoji modifier sequence (skin tone 이모티콘)
│ └ emoji flag sequence (국기 이모티콘)
├ emoji zwj sequence (가족 이모티콘, 직업 이모티콘 등)
└ emoji tag sequence (TAG 이모티콘)
다음에는 emoji sequence의 요소에 관해 설명합니다.
Emoji Combining Sequence (결합 문자)
Non spacing mark (결합 문자; 자체는 폭을 가지지 않고, 이전의 문자에 결합하여 하나의 형태가 되는 문자)를 포함하는 이모티콘입니다.
지금까지 non spacing mark로 U+20E3 COMBINING ENCLOSING KEYCAP을 가지는 1️⃣ 등의 결합 문자만 포함되어 있습니다.
예 : U+0031 U+FE0F U+20E3 Keycap Digit One 1️⃣
(참고 : OS X El Capitan라면 ↑ 이모티콘이 제대로 표시되지 않습니다) http://emojipedia.org/keycap-digit-one/
| 코드 포인트 | 문자 | 설명 |
|---|---|---|
| U+0031 | 1 | DIGIT ONE |
| U+FE0F | N/A | VARIATION SELECTOR-16 (EPVS) |
| U+20E3 | ⃣ | COMBINING ENCLOSING KEYCAP |
Emoji Modifier Sequence (skin tone 이모티콘)
이모티콘 중 인체의 피부가 노출된 문자 (Emoji_Modifier_Base property이 Yes인 문자) 뒤에 Emoji_Modifier (U+1F3FB..U+1F3FF EMOJI MODIFIER FITZPATRICK TYPE 1-2..6)를 붙여서 피부 색상을 변경한 이모티콘입니다.
이 종류의 이모티콘은 인류의 다양성을 이모티콘에 반영시켜 전세계의 사람들이 이모티콘을 사용할 수 있도록 하기 위해 2015-06-17에 발표되어 Unicode 8.0에 도입된 것입니다.
예 : U+1F44F U+1F3FD Clapping Hands Sign, Type-4 👏🏽
http://emojipedia.org/clapping-hands-sign-type-4/
| 코드 포인트 | 문자 | 설명 |
|---|---|---|
| U+1F44F | 👏 | CLAPPING HANDS SIGN |
| U+1F3FD | 🏽 | EMOJI MODIFIER FITZPATRICK TYPE-4 |
Emoji Flag Sequence (국기 이모티콘)
U+ 1F1E6..U+1F1FF REGIONAL INDICATOR를 두 개 붙인 이모티콘입니다.
Unicode emoji의 국기는 A부터 Z까지의 알파벳 1문자를 나타내는 문자 REGIONAL INDICATOR를 두 개 붙여서 표시됩니다.
예 : U+1F1EF U+1F1F5 Flag for Japan 🇯🇵
http://emojipedia.org/flag-for-japan/
| 코드 포인트 | 문자 | 설명 |
|---|---|---|
| U+1F1EF | 🇯 | REGIONAL INDICATOR SYMBOL LETTER J |
| U+1F1F5 | 🇵 | REGIONAL INDICATOR SYMBOL LETTER P |
Emoji ZWJ Sequence (가족 이모티콘, 직업 이모티콘 등)
U+200D ZERO WIDTH JOINER (ZWJ)에 의해 여러 이모티콘을 연결해 1문자로 보여주는 이모티콘입니다. 주로 가족 이모티콘, 직업 이모티콘에 사용됩니다.
이 종류의 이모티콘도 skin tone 이모티콘처럼 인류의 다양성, 특히 gender equality를 이모티콘에 반영하기 위해 도입되었습니다.
예 : U+1F468 U+200D U+1F468 U+200D U+1F466 Family: Man, Man, Boy 👨👨👦
http://emojipedia.org/family-man-man-boy/
| 코드 포인트 | 문자 | 설명 |
|---|---|---|
| U+1F468 | 👨 | MAN |
| U+200D | N/A | ZERO WIDTH JOINER |
| U+1F468 | 👨 | MAN |
| U+200D | N/A | ZERO WIDTH JOINER |
| U+1F466 | 👦 | BOY |
예 : U+1F6B5 U+1F3FC U+200D U+2640 U+FE0F Woman Mountain Biking, Type-3 🚵🏼♀️
(참고 : OS X El Capitan라면 ↑ 이모티콘이 제대로 표시되지 않습니다) http://emojipedia.org/woman-mountain-biking-type-3/
| 코드 포인트 | 문자 | 설명 |
|---|---|---|
| U+1F6B5 | 🚵 | MOUNTAIN BICYCLIST |
| U+1F3FC | 🏼 | EMOJI MODIFIER FITZPATRICK TYPE-3 |
| U+200D | N/A | ZERO WIDTH JOINER |
| U+2640 | ♀ | FEMALE SIGN |
| U+FE0F | N/A | VARIATION SELECTOR-16 (EPVS) |
Emoji TAG Sequence (TAG 이모티콘)
기존의 이모티콘에 대해서 머리 색깔이나 이모티콘 방향 등을 변경해서 다양한 변화를 구현하는 태그를 붙인 것 …… 같지만, 내가 아는 한, 현재 Andorid/iOS의 표준 키보드로 emoji TAG sequence를 입력할 수 없는 것 같습니다.
이것에 대해 자세하게 알아보지 않았지만, Proposed Draft UTS #52: UNICODE EMOJI MECHANISMS에는 자세한 설명 (초안)이 있는 것 같습니다.
Part II. 이모티콘 처리
여기에서는 실제로 프로그램에서 이모티콘 처리에 문제가 될 수 있는 사항을 처리합니다.
이모티콘 문자 카운트
프로그램에서 사용자 입력값을 다룰 때 가끔 문자 수가 필요합니다. 그런데 이모티콘 문자 수를 카운트하려면 종종 이상한 값이 됩니다.
irb(main):001:0> RUBY_VERSION
=> "2.3.1"
irb(main):002:0> "1️⃣".scan(/\X/).count
=> 3
irb(main):003:0> "👏🏽".scan(/\X/).count
=> 2
irb(main):004:0> "👨👨👦".scan(/\X/).count
=> 5
irb(main):005:0> "🇯🇵".scan(/\X/).count
=> 2
irb(main):006:0> "🇯🇵🇯🇵🇯🇵".scan(/\X/).count
=> 6
이것은 ruby의 String#length가 코드 포인트 단위로 문자 수를 세므로에서 복수 코드 포인트로 구성된 이러한 이모티콘의 “외형상” 문자 수를 세자면 unicode에서 grapheme cluster의 개념이 필요합니다.
grapheme cluster
grapheme cluster 란, unicode에서 자연스러운 “1문자”를 나타내는 단위입니다. Unicode에 의한 문자의 일부는 복수의 코드 포인트로 구성 (예 : U+0061 U+0301 á)되지만, grapheme cluster를 이용하면 이를 1문자마다 분할할 수 있습니다.
grapheme cluster에 대한 다양한 기사에서 설명하므로 일부 소개합니다 :
- Unicode의 grapheme cluster - hydrocul 메모
- 문자 수를 카운트하는 7가지 방법 - LINE Engineers’ Blog
- 왜 Swift 문자열 API는 어려운가 - POSTD
이모티콘 문자 카운트에 grapheme cluster를 사용하면 좋으므로 ActiveSupport 5.0 의 ActiveSupport::Multibyte::Unicode.unpack_graphemes 를 사용해봅시다.
irb(main):001:0> load 'unicode.rb'
=> true
irb(main):002:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("1️⃣").count
=> 1
irb(main):003:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("👏🏽").count
=> 2
irb(main):004:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("👨👨👦").count
=> 3
irb(main):005:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("🇯🇵").count
=> 1
irb(main):006:0> ActiveSupport::Multibyte::Unicode.unpack_graphemes("🇯🇵🇯🇵🇯🇵").count
=> 1
이렇게 하면 단순하게 코드 포인트를 계산하기보다 실제에 가까운 값을 얻을 수 있었지만 …… 아직 이상하네요. 가족 이모티콘은 인원수 계산되었고, 마지막 국기는 3문자인데 1문자로 계산되었습니다.
이것은 rails 5.0.0 ActiveSupport::Multibyte::Unicode.unpack_graphemes 가 Unicode 8.0.0 이하의 버전에 따라 grapheme cluster를 분할하기 때문에 발생하는 문제입니다. 또한 Swift 3.1 の String.characters.count 등을 사용해도 같은 결과를 얻을 수 있습니다.
grapheme cluster의 Unicode 9.0 이상과 8.0 이전의 차이
grapheme cluster의 분할 규칙은 USA #29: Unicode Text Segmentation 으로 정해져 있습니다. 이 중 최신 Unicode 9.0에 대응하는 Revision 29 와 Unicode 8.0에 대응하는 Revision 27 은 이모티콘의 처리가 다음과 같이 변경되어 있습니다.
| 항목 | Unicode 8.0 | Unicode 9.0 |
|---|---|---|
| Emoji modifier sequence (skin tone 이모티콘) | 분할한다 (※) | 미분할 |
| Emoji zwj sequence (가족 이모티콘, 직업 이모티콘 등) | 분할한다 (※) | 미분할 |
| Emoji flag sequence (국기 이모티콘) | 미분할 | 홀수 항목에서는 미분할 |
(※ Emoji modifier sequence 등의 개념이 Unicode 9.0에서 추가된 것이므로, Unicode 8.0 이전 버전에서는 “기타 (특별한 처리가 필요 없는지 일반) 문자로 처리된 결과, 분할된다」라는 것이고 “일부러 나누기”라는 것은 없다.)
따라서 위의 ActiveSupport::Multibyte::Unicode.unpack_graphemes 을 이용한 예에서도 skin tone 이모티콘 ZWJ와 skin tone modifier로 분할되어, 국기 이모티콘은 몇 문자 계속되어도 1문자로 계산됩니다.
이모티콘 문자 수를 제대로 계산하려면
이모티콘 문자 수를 엄격하게 제대로 계산하려면, Unicode 9.0 이상을 지원하는 최신 USA #29에 따라 Parser가 필요합니다.
Ruby 2.4.0은 Unicode 9.0 에 대응 하므로 2016-12-12에 발표된 ruby 2.4.0-rc1 을 사용하면 다음과 같이 올바른 문자 수를 얻을 수 있습니다.
irb(main):001:0> RUBY_VERSION
=> "2.4.0"
irb(main):002:0> "1️⃣".scan(/\X/).count
=> 1
irb(main):003:0> "👏🏽".scan(/\X/).count
=> 1
irb(main):004:0> "👨👨👦".scan(/\X/).count
=> 1
irb(main):005:0> "🇯🇵".scan(/\X/).count
=> 1
irb(main):006:0> "🇯🇵🇯🇵🇯🇵".scan(/\X/).count
=> 3
그러나 아직 정식 출시 전인 ruby 2.4.0을 실제 서비스에 투입하는 것은 어려울 것입니다.
필자가 이 문제에 직면한 2016-08 시점에는 Unicode 9.0.0에 대응한 Parser는 (필자가 찾은 바로는) 못 찾았고, 스스로 구현했습니다.
그러나 Unicode 9.0.0을 엄격하게 준수하기 위해서는 unicode_tables.dat 와 같은 Unicode 문자의 데이터베이스가 필요한 것 이외에 USA #29를 읽어야 하므로 장애물이 높습니다. 이를 피하려면, 예를 들어 Ruby에서 이모티콘을 포함하는 문자열 길이를 카운트하고 싶다 에서 소개된 바와 같이 다음과 같은 방침에 엉성한 구현이 가능합니다.
- Variation selector, skin tone modifier와 결합 이모티콘
U+20E3 ENCLOSING KEYCAP은 세지 않는다. - 국기 이모티콘을 나타내는 regional indicator는 2개를 1문자로 계산한다.
- Zero width joiner만큼 전체 길이를 마이너스한다.
여기에서는 위를 구현한 엉성한 문자 수 카운터 를 준비했습니다. 출력이 여기에 있습니다 :
$ ruby length.rb
RUBY_VERSION = 2.3.1
"1️⃣".length = 3
"1️⃣".codepoints.count = 3
"1️⃣".scan(/\X/).count = 1
lesser_graphemes_counter("1️⃣") = 1
"👏🏽".length = 2
"👏🏽".codepoints.count = 2
"👏🏽".scan(/\X/).count = 2
lesser_graphemes_counter("👏🏽") = 1
"👨👨👦".length = 5
"👨👨👦".codepoints.count = 5
"👨👨👦".scan(/\X/).count = 5
lesser_graphemes_counter("👨👨👦") = 1
"🇯🇵".length = 2
"🇯🇵".codepoints.count = 2
"🇯🇵".scan(/\X/).count = 2
lesser_graphemes_counter("🇯🇵") = 1
"🇯🇵🇯🇵🇯🇵".length = 6
"🇯🇵🇯🇵🇯🇵".codepoints.count = 6
"🇯🇵🇯🇵🇯🇵".scan(/\X/).count = 6
lesser_graphemes_counter("🇯🇵🇯🇵🇯🇵") = 3
스스로 구현한 lesser_graphemes_counter() 만 제대로 문자 수를 출력합니다.
…… 물론 이런 엉성한 구현에는 예를 들어 regional indicator가 1개만 존재하는 경우나, zero width joiner 전후에 이모티콘이 아닌 문자가 존재하는 경우에는 올바른 문자 수 차이가 납니다. 그것은 적절히 합니다. 필자의 환경에서는 좀 더 정직한 Parser가 구현되어 실제로 동작합니다 (하지만 시간이 부족해서 이번 기사에서 소개할 수는 없습니다 … 조금 기다리면 각 언어와 프레임워크가 Unicode 9.0 이상에 대응하므로, 우선 엉성한 구현으로 극복하는 것도 하나의 선택이라고 생각합니다.)
이모티콘 표시 스타일이 환경에 따라 달라지는 문제
“이모티콘을 텍스트 스타일과 이모티콘 스타일 중 어느 쪽을 표시할 것인가”에 대해서 UTR #51에서는 다음과 같이 표시되어 있습니다.
- Variation selector가 붙어 있으면 그에 따른다.
- 그렇지 않다면 각 문자의
Emoji_Presentationproperty에 정해진 기본값에 따른다. 그러나 환경에 따라 기본값은 무시될 수 있다.
(표: UTR #51 인용・재개)
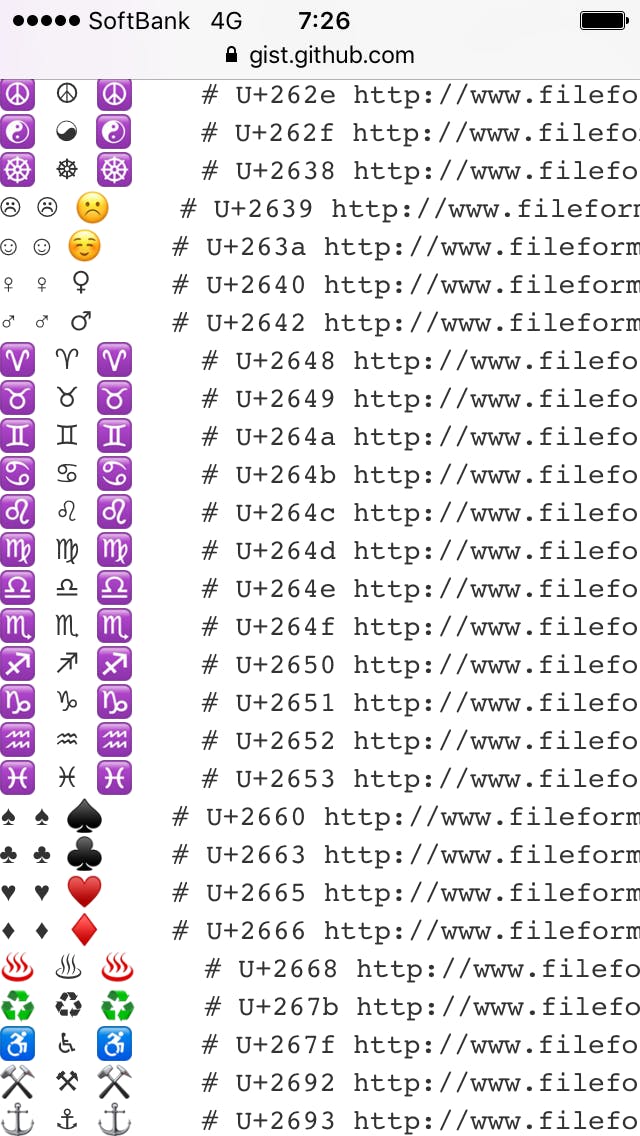
그렇다면 “환경에 따른”이라는 것은 구체적으로 어느 정도의 차이가 있을까요? 이를 검증할 페이지를 준비했습니다 (Part I. 에서 게재한 것을 재게) :
- sobataro/emoji_list.txt (기본 이모티콘, TPVS 포함 이모티콘, EPVS 포함 이모티콘 목록)
- sobataro/emoji_list.rb (↑를 생성한 스크립트)
이 페이지를 iOS 10.2 (iPhone 5S), Android 7.1.1 (Nexus 5X), Android 5.1.1 (Xperia Z Ultra)에서 표시했을 때의 스크린 샷을 아래에 추가합니다 :
| iOS 10.2 (iPhone 5S) | Android 7.1.1 (Nexus 5X) | Android 5.1.1 (Xperia Z Ultra) |
|---|---|---|
 |
 |
 |
이 화면에서도 환경에 따라 꽤 차이가 있는 것을 알 수 있습니다. 예를 들어 variation selector가 없는 기본 표시 (가장 왼쪽 열)은 다음과 같은 차이가 있습니다 :
| 문자 | iOS 10.2 | Android 7.1.1 | Android 5.1.1 |
|---|---|---|---|
| U+262E PEACE SYMBOL ☮ | emoji | text | tofu |
| U+263A WHITE SMILING FACE ☺ | text | emoji | emoji |
| U+2665 BLACK HEART SUIT ♥ | text | emoji | text |
이 표시 스타일을 각 환경에서 검증한 결과, 다음과 같은 느낌점(어디까지나 느낌점입니다)을 얻을 수 있었습니다 :
- iOS
Emoji_Presentationproperty를 거의 무시하고 대부분의 문자가 기본적 이모티콘 표시가 된다.- 기본적으로 텍스트 표시가 되는 문자는 20자 정도 적다.
- iOS 10.1과 10.2에서 기본 스타일에 약간의 차이가 있는 것 같았다.
- Android 7 이상
- Unicode가 정하는
Emoji_Presentationproperty에 대부분을 따른 스타일을 표시하고 있다 (그러나 일부 예외도 있다). - 그 결과, 기본적으로 텍스트 표시되는 문자가 그럭저럭 많다 (100 자 정도).
- Unicode가 정하는
- Android 6 이전
- 원래 variation selector을 대응하지 않기 때문에 variation selector의 유무와 관계없이 하나의 스타일로 표시된다.
- 각 이모티콘 스타일 선택은 단말이 가지는 폰트 파일에 의존하고 있고, 제조사나 단말마다의 차이도 크다.
- 기존 단말 (특히 Android 4 버전)은 흑백 문자나 컬러 계열 이모티콘과 유사한 이모티콘으로 보인다.
- (추가) OS X El Capitan
- 조금밖에 확인 안 했지만, Unicode에서 정하는
Emoji_Presentationproperty에 대체로 (완전?) 따르는 것 같다.
- 조금밖에 확인 안 했지만, Unicode에서 정하는
각 환경에서 표시 스타일을 통일하는 방법으로는 다음에 소개하는 twemoji과 noto-emoji를 이용하면 좋을 것입니다.
각 환경에서 이모티콘 스타일을 통일하고 싶다 / 이모티콘 파일을 앱이나 서비스에 포함해서 제공하고 싶다 / 서버 사이드에서 이모티콘을 이용하고 싶다
Twitter의 twemoji 와 google의 noto-emoji 를 사용합시다.
- twemoji
- 이미지 파일 형식으로 배포된다.
- CDN 경유로 사용 할 수 있으며 문장 중에 이미지 파일의 `` 태그를 삽입 javascript 도 포함한다.
- 스크립트 등의 추가 소스 코드는 MIT License, 이모티콘 이미지 파일은 CC-BY 4.0 라이센스가 된다.
- noto-emoji
- 이미지 파일 및 글꼴 파일 형식으로 배포된다.
- 글꼴 파일을 사용하여 일반 텍스트와 다른 폰트와 함께 사용하기 쉬운.
- 글꼴 파일은 SIL Open Font License v1.1, 기타 (이모티콘) 이미지 파일과 함께 소스 코드는 Apache License v2.0 라이센스된다.
정리
이모티콘을 다루는데 있어서 여러 가지 함정이 있다는 것을 알게 되었습니다. 특히 iOS 나 Android의 최신 버전은 최신 이모티콘이 “사용 가능”할 수 있게 되어있지만, “사용 가능”해도 키보드에서 입력하고 볼 수 있는 것만이고, 문자 수 카운트 및 삭제로 문제가 일어나기도 하고 큰 골칫거리가 있다고 생각합니다. 그럴 때 이 기사가 도움이 되었으면 합니다.
이 글은 mixi Group Advent Calendar 2016 18일째 글입니다. 어제는 @radioboo 님의 IGListKit에서 Feed UI를 리팩토링 입니다. 내일은 @yusuke_tashiro 씨 담당입니다.
Currnte Pages Tags
Subscribe
Subscribe to this blog via RSS.
Categories
Recent Posts
- Posted on 19 Apr 2026
- Posted on 15 Mar 2026
- Posted on 10 Mar 2026
- Posted on 30 Dec 2025